Fusión de datos
La fusión de datos consiste en reunir múltiples flujos de datos en uno solo. Dependiendo de las necesidades de tu flujo de trabajo, puedes utilizar distintos nodos para lograr esta operación:
- Fusionar datos provenientes de diferentes flujos o nodos: utiliza el nodo Merge para fusionar datos de múltiples orígenes en un único flujo.
- Fusionar datos generados por múltiples ejecuciones de un mismo nodo: emplea el nodo Code para manejar escenarios complejos, como combinar los resultados de varias ejecuciones del mismo nodo o de varios nodos.
- Comparar y fusionar datos: usa el nodo Compare Datasets para comparar flujos de datos antes de fusionarlos, y generar un resultado basado en los hallazgos de la comparación.
Las siguientes secciones explican cada método con detalle.
Fusionar datos de diferentes flujos de datos
Si tu flujo de trabajo se bifurca en múltiples ramas, puedes volver a unir esos flujos independientes en uno solo.
Este es un flujo de trabajo de ejemplo que muestra distintos tipos de fusión: añadir conjuntos de datos, conservar solo elementos nuevos o conservar solo elementos existentes. La documentación del nodo Merge incluye una descripción detallada de cada operación de fusión.
Ver detalles del flujo de trabajo de ejemplo
Fusionar datos de diferentes nodos
Incluso si tu flujo de trabajo no se divide en múltiples flujos independientes, puedes usar el nodo Merge para fusionar los datos procedentes de dos nodos anteriores. Esto resulta muy útil cuando necesitas reunir los datos generados por varios nodos en una única salida.
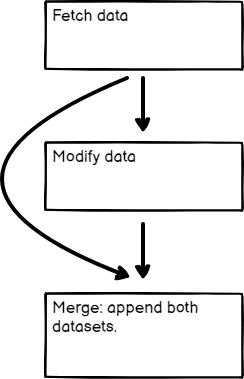
Fusión de datos de dos nodos anteriores
Fusionar datos de múltiples ejecuciones de un nodo
Puedes usar el nodo Code para fusionar los datos generados por múltiples ejecuciones del mismo nodo, lo cual es especialmente útil en ciertos escenarios con bucles.
Ejecución de nodos vs. ejecución de flujos de trabajo
Esta sección describe cómo fusionar los datos producidos por múltiples ejecuciones de un mismo nodo dentro de una única ejecución del flujo de trabajo.
Consulta este flujo de trabajo de ejemplo que utiliza los nodos Loop Over Items y Wait para simular múltiples ejecuciones.
Ver detalles del flujo de trabajo de ejemplo
Comparar conjuntos de datos
El nodo Compare Datasets compara flujos de datos antes de fusionarlos y puede generar hasta cuatro flujos de salida distintos.
Consulta este flujo de trabajo de ejemplo para ver su uso en la práctica.